模型剪枝领域,2015-2020论文合集,根据github上awesome-pruning 下载整理的,包括基本所有的论文和综述,已分类整理重命名(如CVPR2020-论文名)十分全,强烈建议下载阅读~
”模型剪枝 论文 2015-2020 模型剪枝综述“ 的搜索结果
模型剪枝领域,2015-2020论文合集,根据github上awesome-pruning 下载整理的,包括基本所有的论文和综述,已分类整理重命名(如CVPR2020-论文名)十分全,强烈建议下载阅读~ 相关下载链接://download.csdn.net/...
Learning Efficient Convolutional Networks through Network Slimming 摘要: CNN在落地中的部署,很...该方法非常适用于CNN的结构,可将训练的开销降到最低,并且生成的模型不需要特定的软硬件进行加速,部署性能更高
论文:...这篇论文一定要好好研究下,提出该剪枝方法的是暗物智能科技&中山大学,当初去面试过该公司,聊了将近一小时,大部分是关于剪枝的内容。。。。。。。可惜自己真实菜如狗。。。。。 ...


在这个综述中,我们讨论了六种不同类型的方法(剪枝、量化、知识蒸馏、参数共享、张量分解和基于线性变压器的方法)来压缩这些模型,使它们能够在实际的工业NLP项目中部署。
文章目录非结构化的Learning both Weights and Connections for Efficient Neural ...本文记录一下对model pruning方法的学习,我只是挑了一些代表性的论文阅读一下,了解pruning的思路。 首先推荐一篇博客,闲话模型
总结一下最近看的关于剪枝的论文
标签: 剪枝

文章目录一、论文背景二、算法优势分析三、算法思路四、识别感知损失的构建五、最小化结合误差六、终止条件七、实验结果八、代码测试九、个人理解 一、论文背景 深度学习发展之后,为了让计算机视觉任务的性能,大...

先是看了一篇综述,希望对现有或以往的模型优化有个大概了解。 [1]赖叶静,郝珊锋,黄定江.深度神经网络模型压缩方法与进展[J].华东师范大学学报(自然科学版),2020(05):68-82. Introduction 背景: DNN的高内存消耗与...
接触剪枝是最近一段时间的事情,为了全面的系统的学习一下剪枝,笔者做了个论文综述。从2016年的韩松的deep compression 到最新的彩票假设,我主要是将剪枝可以分为三个大类。分别是不需要数据参与的硬剪枝,带数据...
来自中国科学院和人民大学的研究者们深入探讨了基于LLM的模型压缩研究进展并发表了该领域的首篇综述《A Survey on Model Compression for Large Language Models》。
针对卷积神经网络模型进行了研究,分析了模型中存在的冗余信息,并对国内外学者在神经网络模型压缩方面的研究成果整理,从参数剪枝,权重共享和权重矩阵分解等方面总结了神经网络压缩的主要方法。最后针对神经网络...

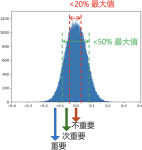
基于度量标准的剪枝 这类方法通常是提出一个判断神经元是否重要的度量标准,依据这个标准计算出衡量神经元重要性的值,将不重要的神经元剪掉。在神经网络中可以用于度量的值主要分为3大块:Weight / Activation / ...
A survey on security and privacy of federated learning Viraaji Mothukuri a, Reza M. Parizi a, Seyedamin Pouriyeh b, Yan Huang a, Ali Dehghantanha c, Gautam Srivastava d,e,∗ a The Department of ...
1 摘要 通过从网络中删除不重要的权重,可以有更好的泛化能力、需求更少的训练样本、更少的学习或分类时间。本文的基础思想是使用二阶导数将一个训练好的网络,删除一半甚至一半以上的权重,最终会和原来的网络性能...

在快速发展的人工智能(AI)领域中,生成式大型语言模型(llm)站在了最前沿,彻底改变了论文与数据交互的方式。然而,部署这些模型的计算强度和内存消耗在服务效率方面带来了重大挑战,特别是在要求低延迟和高吞吐...
预训练语言模型,如BERT,已被证明在自然语言处理(NLP)任务中非常有效。然而,在训练中对计算资源的需求很高,因此阻碍了它们在实践中的应用。为了缓解大规模模型训练中的这种资源需求,本文提出一种Patient知识蒸馏...

在权重回溯中,我们首先训练一个大型神经网络(也称为原始网络),然后剪枝该网络,保留一些重要的权重并去除其他不重要的权重。除了在权重级别的非结构化修剪和在滤波器级别的结构化修剪之外,还有其他粒度的修剪...
PaddleSlim是百度提出的模型优化工具,包含在PaddlePaddle框架中,支持若干知识蒸馏算法,可以在teacher网络和student网络任意层添加组合loss,包括FSP loss,L2 loss,softmax with cross-entropy loss等。...


(ResRep)(2021)将CNN重参数化为两个部分,一个为记忆部分,保持学习性能,第二个为遗忘部分,在BN层之后插入1*1卷积或者compactors,训练更新梯度时仅作用于compactors,即只允许compactors遗忘,而其他卷积层保持...
推荐文章
- cocos creator 实现截屏截图切割转成 base64分享--facebook小游戏截图base64分享,微信小游戏截图分享【白玉无冰】每天进步一点点_cocos上传base64-程序员宅基地
- Docker_error running 'docker: compose deployment': server-程序员宅基地
- ChannelSftp下载目录下所有或指定文件、ChannelSftp获取某目录下所有文件名称、InputStream转File_channelsftp.lsentry获取文件全路径-程序员宅基地
- Hbase ERROR: Can‘t get master address from ZooKeeper; znode data == null 解决方案_error: can't get master address from zookeeper; zn-程序员宅基地
- KMP的最小循环节_kmp求最小循环节-程序员宅基地
- 详解ROI-Pooling与ROI-Align_roi pooling和roi align-程序员宅基地
- Imx6ull开发板Linux常用查看系统信息指令_armv7 processor rev 2 (v7l)-程序员宅基地
- java SSH面试资料-程序员宅基地
- ant design vue table 高度自适应_对比1万2千个Vue.js开源项目发现最实用的 TOP45!火速拿来用!...-程序员宅基地
- 程序员需要知道的缩写和专业名词-程序员宅基地